
Author: jaywll
Making Google Analytics Work for Me (and You)
When I put my website together back whenever it was that I did that, I knew I wanted to get analytics from it: at the beginning the site was fairly simple (this blog, for example, was an entirely separate entity back then and it wasn’t integrated into the site in the way it is today), but from the start I wanted to know how many visitors I was getting, where they were in the world, how they were finding me, and a little about how they were interacting with my site.
I’d used Google Analytics on past projects, but this time around I felt a little uneasy about providing Google with an easy way to gather data on all my site visitors. Those guys have enough power without me contributing. I went with clicky.com for my analytics, and all was well.
In researching this post I found an article called Seven Reasons Why You Should NOT Use Google Analytics. My concerns about giving Google too much power rank number four in their list, but they ultimately reach the same conclusion I did – Google’s product offering in this space is simply better than the alternatives out there, especially when you consider the price (free). With Clicky the basic service is free but limited – you need to fork over some cash if your site generates a lot of traffic, or you want to retain data for longer than 31 days, or add advanced features… the list goes on.
I switched back to Google’s service a couple of weeks ago and I haven’t looked back. While I was at it I not only added the relevant code to this site, I also added it to Flo’s blog and the jnf.me landing page. Clicky limited me to tracking a single site but Google doesn’t, so why not?

For a website like mine adding the relevant JavaScript to the site and then forgetting about it is a reasonable approach, but I’ve discovered very quickly that if you’re prepared to put in a little more effort then you can get much improved results. For me, this was highlighted by the extremely limited usefulness of the data I’ve been getting from JNF.me, but the way I’m solving that problem could apply anywhere. Read on!
The Problem
When I bought the domain jnf.me my primary concern was getting something short. My plan all along was to use sub-domains for the various bits of content that lived under it (www.jason.jnf.me, www.asiancwgrl.jnf.me, and so on). The J stands for Jason, the F for Flo, and the N for ‘n, but that’s not really relevant. Since it is the root of my domain, I knew I should put something there so I created a quick, fairly simple, single-page site. The page is divided into two with me on the left and Flo on the right, and if you click one of our faces then the whole thing slides over to reveal a little about us and some links to our online content.
In terms of analytics data, the very fact that this is a single-page site is what’s causing issues. With a larger like jason.jnf.me even taking the most basic approach to installing Google Analytics tells me, for example, that the average visitor views three pages. I know which pages are the most popular, which blog topics generate the most interest, and so on.
With JNF.me I know that people visit the page and then their next action is to leave again – but of course it is, there is only that one page.
What are they doing while they’re there? Are they leaving through one of the links on the page? I have no idea, but I can find out.
Manually Sending Pageviews
The first thing I opted to do was manually send a pageview to Google Analytics when somebody clicks one of our pictures to slide out the relevant content from the side of the page.
My rationale for this approach is that if this were a site with a more traditional design, clicking a link to view more content from the site would indeed cause another page to be loaded. The fact that my fancy design results in the content sliding in from the side instead really makes no difference.
The approach is extremely simple, and adding a single line of JavaScript to the code that makes the content slide in is all it took:
ga('send', 'pageview', {'page': '/' + p });
So how does this work? ga() is a function that Google Analytics creates when it’s first loaded by the page, and in fact if you’re using Google Analytics at all then you’re already using this. Let’s take a quick look at the code Google has you paste into your page in order to start feeding data to Analytics in the first place. It ends with these two lines:
ga('create', 'UA-XXXXXXXX-X', 'auto');
ga('send', 'pageview');
The first line initializes things and lets Google know (via the UA-XXXXXXXX-X bit) which Analytics account it’s going to be getting data for. The second line sends a pageview to Analytics because, well, if the code is being executed then that means somebody is viewing the page.
By default Analytics makes the perfectly reasonable assumption that the page that executes this code is the one it should be recording a pageview for, but here’s the thing: it doesn’t have be that way.
Back to my example, and you’ll notice I’ve added a third argument to the ga() function call. Google’s help page on the subject discusses the options in terms of possible parameters, but essentially what I’m doing is passing a JavaScript object that describes exactly what Analytics should track. The page field is the page address against which a pageview is registered, and the p variable is used elsewhere in my code that makes the sliding content work: it stands for person, and it contains either “jason” or “flo” as appropriate.
The important thing to note here is that these pages don’t exist – there is nothing on my website at either /jason or /flo – but this doesn’t matter. Analytics registers a pageview for one of these addresses anyway, and I know when I see it in my data that it means that somebody opened the sliding content.
Sending Events
In addition to sending pageviews to Analytics you can also send events, and this is the approach I took to help me understand how people are leaving the page.
When I first started learning about events I spent some time trying to understand the right way to use them. Google’s Event Tracking help page provides an example, and you can find some good reading material about it on the web. The conclusion I’ve reached from my brief research is that there is no “right” way to use events – you just define them in whatever way works best for you, your site, and your desired outcome.
The important thing to know is that events have, as a minimum, an associated category and action. You can also optionally define a label and a value.
I can see that the value parameter would be extremely useful in some scenarios, such as tracking e-commerce sales (you could, for example, use Analytics to track which traffic sources result in the highest sales figures in this way) but I don’t need that. I will be using the other three parameters, though.
When you view data regarding events in the Analytics interface, they’re in something of a hierarchical structure. Categories are treated separately from one another, but you can view summary data at the category level, then drill-down to segment that data by action, then drill down further to segment by label.
For the events fired when a site visitor clicks an external link on my page I arbitrarily decided that the category would be ‘extlink,’ the action would be the person the link relates to (either jason or flo), and the label would be indicative of the link destination itself (blog, twitter, etc).
To implement this, the first thing I did was add a class and a custom data attribute to the links on the page:
<a href="http://twitter.com/JayWll" class="outbound" data-track="jason/twitter">Twitter</a>
The class of outbound defines this as an outbound link as opposed to one of the links that helps visitors navigate around the page, slide content in and out, etc, and the data-track attribute defines what will become the event’s action and label.
Next, the JavaScript. This time around it’s slightly more in-depth than the single line of code we used to send a pageview. That’s not necessarily a function of events as compared to pageviews, but it’s due to the nature of what I’m tracking here: when a user clicks a link that takes them away from the current page, they (by default) leave immediately. In order to track outbound links, I actually need to hold them up and make sure the event is registered with Analytics before I let them go anywhere. Happily, Google has thought of that and the ga() function accepts a hitCallback property. This is a function that’s fired only once the event has been properly recorded.
Here’s my code:
$('a.outbound').click(function(e) {
e.preventDefault();
trURL = $(this).attr('data-track');
nvURL = $(this).attr('href');
ga('send', 'event', {
'eventCategory': 'extlink',
'eventAction': trURL.split('/')[0],
'eventLabel': trURL.split('/')[1],
'nonInteraction': 1,
'hitCallback': function() {
location.href = nvURL;
}
});
});
The first thing I do is prevent the link’s default behaviour with the line
e.preventDefault();
Next, I capture the link’s data-track and href attributes – we’ll need both of those later.
Finally, we’re back to the ga() function to send data to Analytics. We send an event, and define its parameters within the JavaScript object: the category is ‘extlink,’ the action and label are obtained by splitting the link’s data-track attribute, we define this as a non-interaction event (LMGTFY) and, once this data has been successfully sent, the hitCallback function is executed which takes us to the page specified by the link’s href attribute.
Easy, when you know how.
Taking it Further
The possibilities here are endless, and how use them really depends on your site and the data you’d like to get from it. My plan is to take some of what I’ve learned for jnf.me and extend it to this site, particularly in regards to event tracking.
In addition to tracking outbound links, I have two other ideas for how I might use this:
- Page length and scroll tracking
Some of my posts – this one is potentially a prime example – are pretty long. I do tend to ramble on a bit at times. If a post is more than, say, two screen heights in length then I could track how many people scroll beyond the halfway point and how many people scroll to the end to help me understand if my audience is OK with long posts or if I should split in-depth content into some kind of mini-series. - Form tracking
There’s a contact me page on this site, and each post in this blog has a comment form at the bottom. With events I could gain a much better understanding of how these are working and how visitors interact with these forms. For example, do people begin filling out the contact me form but then abandon it at some point before submitting? Do people begin to write comments on my posts but then refrain from posting it when they find out I require them to at least provide their email address?
Hopefully you have ideas for how you can use these techniques to provide better insight into visitor behaviour on your site too. Come back here and leave a comment to let me know how it goes! I do require your email address for that, but I promise not to spam you or pass it on to any third party.
Late Night Links – Monday August 4th, 2014
It’s that time of the week again! Except of course it isn’t and I should have done this yesterday, but oh well. What are long weekends for if not procrastinating and ignoring arbitrary self-inflicted deadlines, eh?
- Things You Can’t Do When You’re Not a Toddler
- Sure Enough, You Can Play ‘Doom’ on an ATM
All ATMs should do this. - Next-Generation Lithium Cells Will Double Your Phone’s Battery Life
- Intersections: Still Not a Good Place for Naps
- Quiznos Rep David
This is amazing. - Cutting Corners
China’s built a rectangular running track, presumably because it’s easier than curved. - Pinterest Acquires Icebergs, The Pinterest for Creatives
I didn’t know there was such a thing as icebergs. I might check it out. I consider myself a “creative.” - Calgary Commode Makes List of Canada’s Top 5 Bathrooms
Flo went to the zoo a couple of days ago with her sister and our newphew. I wonder if they took in the bathroom exhibit while they were there? Also, penguins. - Things You Can’t Do When You’re Drunk
I feel you could probably get away with a few things from the first video though, so there’s that. - 12 Years After Its Debut on Hacked XBoxes, XBMC Changes Its Name to Kodi
- Email App Lets You “Leak” Your Secrets Without Owning Up to Them
Why is this a thing? This can’t be good, surely?
And that’s it, we’re all done! I’ll be back here in just six short days, internet. See you then.
Your brand is what people say about you when you’re not in the room
Jeff Bezos, founder of Amazon.com
Integrating Microsoft Office Functionality into Your SharePoint Apps
Have you ever come across this snippet of JavaScript before?
try {
xhr = new XMLHttpRequest();
} catch(e) {
xhr = new ActiveXObject(“Microsoft.XMLHTTP”);
}
If you haven’t then not to worry, it’s not really the point of this post anyway – but for the uninitiated this is a snippet of JavaScript that prepares an object that will be used to make an ajax request. Ajax is the mechanism by which a webpage can load more data from the server even after the page itself has finished loading, and you find it all over the place.
The reason I bring it up is because of the try… catch construct involved. Essentially it tries to execute the code between the first set of curly braces, and if that fails then it executes the code between the second set instead. In the huge majority of cases the first line of code executes successfully, so why is the second line necessary?
Microsoft. And more specifically, Internet Explorer 6.
For anybody who makes things that live on the web, supporting Internet Explorer 6 is an absolute chore. It does things differently to other (read “standards complaint”) browsers, and you end up having to create everything twice and put a bunch of hacks in place to make your site work with it. The block of code above is a prime example: every other browser has the XMLHttpRequest object built into their JavaScript implementation, but for Microsoft you have to use an ActiveX object instead.
More recent versions of Internet Explorer are much better in this regard, and these days frameworks like jQuery take care of any little annoyances like this that remain so it’s not as big a deal as it was a decade ago, but that’s not the point of this post either.
The point is that ActiveX remains a part of Internet Explorer to this day, and despite the fact that many web programmers know it primarily as a result of the XMLHttp annoyance described above, it does have its uses. So let’s exploit it.
The Downside
If you’ve ever created web content then you’ll know the importance of standards compliance. Writing compliant markup and code helps to ensure that your site works in whatever browser software your end users happen to be using. That’s a good thing.
ActiveX exists only within Internet Explorer. If visitors to your SharePoint webapp are using another browser such as Chrome or Firefox then none of the following example code is going to work for them. The best we’ll be able to do is detect that it hasn’t worked and have our app react in an appropriate way, maybe with a warning message or something similar.
If we were creating something publicly accessible for consumption by a wide variety of internet users then this would be a deal breaker, but in the context of an app built atop SharePoint where all the users are within the four (physical or otherwise) walls of your organization? It might be fine. If your organization is like the one I work for then everybody is using Internet Explorer anyway, because that’s the browser installed on your computer when IT deliver it, and getting them to install an alternative is like pulling teeth.
OK, So What is This ActiveX Thing?
Wikipedia sums it up pretty nicely, including condensing my previous three paragraphs down into a single sentence.
Many Microsoft Windows applications — including many of those from Microsoft itself, such as Internet Explorer, Microsoft Office, Microsoft Visual Studio, and Windows Media Player — use ActiveX controls to build their feature-set and also encapsulate their own functionality as ActiveX controls which can then be embedded into other applications. Internet Explorer also allows the embedding of ActiveX controls in web pages.
However, ActiveX will not work on all platforms, so using ActiveX controls to implement essential functionality of a web page restricts its usefulness.
In other words, one of the things we can use ActiveX for is to take the functionality of a Microsoft application and embed it into a web page. I’m going to put together a fairly simple example, and I’m going to use Excel. Let’s dive in!
The HTML
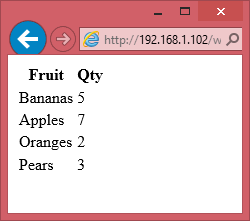
I’m going to build a simple table in HTML. The data in the table could come from anywhere, such as a subset of some SharePoint-based dataset or other pulled together using some of the techniques we’ve looked at previously, or a script executed server-side if you have the ability to create such a thing. For the sake of simplicity though, I’m just going to define in a static manner in my markup – and I’m not going to worry about making it look good.
<table>
<thead>
<tr><th>Fruit</th><th>Qty</th></tr>
</thead>
<tbody>
<tr><td>Bananas</td><td>5</td></tr>
<tr><td>Apples</td><td>7</td></tr>
<tr><td>Oranges</td><td>2</td></tr>
<tr><td>Pears</td><td>3</td></tr>
</tbody>
</table>
The Template
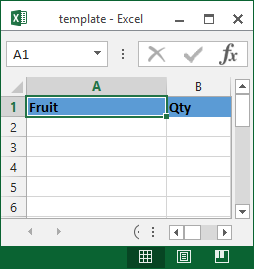
Next, I’m going to define an excel template that we’ll use to place our data into. This could be as detailed or as simple as necessary, so for the purposes of example I’ve gone with simple again. All I’ve done in mine is put headings at the top of column A and B that match the headings in our HTML.
The JavaScript
OK, here’s where the clever bit starts. The first thing we’re going to do is create an ActiveX object pointing to excel, and assign it to a variable so we can reference it again further along in the code.
var exApp = new ActiveXObject('Excel.Application');
Next we’re going to open a new document in excel, based upon our template. Doing this also returns an object that we’ll need again, so we’re going to assign this one to a variable too.
var exDoc = exApp.Workbooks.Add('http://192.168.1.102/web/template.xltx');
It’s important to note here that we have to pass in an absolute reference to the template file – a relative reference is not sufficient because excel has no concept of the location of our webpage. In my test environment the SharePoint server is at 192.168.1.102, but this will undoubtedly be different for you.
At this point, excel is open and has our template loaded, so the next thing to do is iterate over the table in our HTML and plug the data into excel. In general, this is done with the following line of code:
exDoc.ActiveSheet.Cells(1, 1).Value = 'This is row 1, column 1!';
More specifically what we’re going to do is use our old friend jQuery to iterate over the table cells in our HTML page and put them into the right place in excel with the help of a couple of simple counter variables: one for the row we’re targeting, and one for the column. Don’t forget to include a reference to the jQuery library in the document <head> section.
r = 2;
$('table tbody tr').each(function() {
c = 1;
$(this).children().each(function() {
exDoc.ActiveSheet.Cells(r, c).Value = $(this).html();
c++;
});
r++;
});
While we’ve been preparing all this, the Excel window has been invisible to the user. The final step is to make it and its newly imported data appear.
exApp.Visible = true;
Done!
Putting it All Together
The full code of our HTML page is as follows:
<!DOCTYPE html> <html> <head> <title>Export to Excel Example</title> /web/js/jquery-1.11.0.min.js $(document).ready(function() { $('input#export').click(function() { var exApp = new ActiveXObject('Excel.Application'); var exDoc = exApp.Workbooks.Add('http://192.168.1.102/web/template.xltx'); r = 2; $('table tbody tr').each(function() { c = 1; $(this).children().each(function() { exDoc.ActiveSheet.Cells(r, c).Value = $(this).html(); c++; }); r++; }); exApp.Visible = true; }); }); </head> <body> <table> <thead> <tr><th>Fruit</th><th>Qty</th></tr> </thead> <tbody> <tr><td>Bananas</td><td>5</td></tr> <tr><td>Apples</td><td>7</td></tr> <tr><td>Oranges</td><td>2</td></tr> <tr><td>Pears</td><td>3</td></tr> </tbody> </table> <input type="button" id="export" value="Export to Excel"> </body> </html>
Taking it Further
What I’ve put together here is a pretty simple example, but hopefully you can see the value in some of the possibilities this opens up. Getting complex data from a webapp into Excel is actually fairly straightforward.
With a more detailed template to export data into you could prepare webapp data for analysis in excel, create charts, etc, etc.
Enjoy!
The VP of Devil’s Advocacy | TechCrunch
In the 2013 film, World War Z, Gerry Lane (Brad Pitt) is riding through the streets of Jerusalem as Jurgen Warmbrunn (Ludi Boeken) explains how the city was..
Late Night Links – Sunday July 27th, 2014
The weekend may be over, but don’t worry! That just means it’s late night links time again. Let’s get on with it then, shall we?
- This Little Box Hijacks Your Chromecast, Rickrolls Your Living Room
- Twelve Things You Should Do on Your Personal Google+ Account Right Now
I don’t really use my Google+ account at all. I’d like a way to have content from my blog post there automatically, but I can’t find one. - Working on My Novel
- Make it Rain Even Harder with the Cash Cannon
- Too Honest
- Compose Emails and Search Your Gmail Inbox From Chrome’s Address Bar
Handy. - You Can Now Unlock Your Motorola Phone with a ‘Digital Tattoo’
Necessary? - 15 Words and Phrases You’re Probably Saying Incorrectly
I was good on most of these, but numbers 5 and 9 were surprising to me. - Ten Awesome Examples of Material Design
- The Tree That Grows 40 Different Fruit
And that’s it! Next week is a holiday weekend, so I may or may not remember to post some links on time. Here’s hoping!
Home Server Refresh
I get paid every other Thursday, or 26 times a year. That mostly means I get paid twice a month, but twice a year there’s a month where I get paid three times, and this is one of those months.
Since a big chunk of our expenses are monthly, getting paid three times in a month means I have some extra cash left over to play with, and this month I’m going to use it to replace our home server.

Above is our existing home server. It’s a pogoplug device that I’ve hacked to run debian linux. It’s primary function is as network attached storage for all the other devices in the house, and the box to its right is a 2tb USB hard-drive. It also runs a LAMP stack for development, and some torrent software so it can handle downloading duties without any of the other computers in the house needing be kept on.
It only has 256mb of RAM though, and just occasionally if it’s under heavy load things fall down. The torrent daemon is usually the first victim: sometimes I go to check on the status of a download only to find that the downloading process has run out of resources and shut itself down.
My requirements for a replacement are that it handle all the tasks the existing server does – without the problems caused by the limited memory, uses electricity sparingly, and also gives me room to grow and try new things that I haven’t even thought of yet.
My plan is to replace it with a machine I build based on an Intel NUC.

This thing is a barebones machine (it doesn’t include any RAM or storage in the basic package), but it could be useful for many scenarios (I think it would make a great HTPC, for example) including mine.
I’m going to max it out with 8gb of RAM, and this 32-fold increase over what I have now should allow for a whole host of new possibilities.
I’m going to take advantage of the extra resources by attempting to install vSphere Hypervisor on it and split it into a number of virtual servers. One will be linux-based to replicate the functionality of the existing server, one Windows-based VM, and maybe two extra VMs (one linux, one Windows) so I can separate my playing around from mission-critical server duties.
I’ll be posting more as I work my way through the process.
A marriage is always made up of two people who are prepared to swear that only the other one snores
